Developing My Own Custom Input Method Engine
Backstory
I’ve been dreaming about developing a custom Input Method Engine / Editor (IME) for Thai language for quite a long time. I was inspired by a post about the Manoonchai Thai keyboard layout some time in 2022. If I remember correctly, the developer wanted to create a more efficient keyboard layout; like how QWERTY is not the most efficient Latin keyboard layout to type with, the standard Thai Kedmanee layout was developed in the age of the type writer and was not optimized for typing on modern computers.
However, I believe that this misses the actual issue with typing in Thai (no offense to the Manoonchai dev.) From my perspective, the real problem of typing in Thai is caused by having over 60 unique Thai characters mapped onto a keyboard. Because there are so many characters, pressing Shift + a Key will output a different character entirely, rather than an uppercase character (which doesn’t exist in Thai script.) Learning Thai alone is a steep enough learning curve, getting proficient at typing Thai is an absolute chore. I think the actual way to improve Thai typing experience is to change the way you type Thai to begin with.
I believe there are two main options for this:
Firstly, you can develop a completely custom key layout (not based on ANSI/ISO keyboards) specifically for typing Thai. Something like the Japanese 12-key “Flick input”, born from the 12-key mobile phones of yore. I think something this radical is the best option for mobile typing, given the limited screen space and additional input methods available. However, it is not applicable for desktop users (creating a device to replace the keyboard is just not practical). Besides, designing a good custom keyboard layout requires a lot of UX/UI knowledge/research which I just can’t.
Interestingly enough, Apple have developed a 24-key Thai input layout for their upcoming iOS 26 update; which I am very eager to try out for myself.
The second option is to develop a Latin-to-Thai conversion “Input Method Editor” (IME), where the user inputs with Latin keys and a Natural Language Processing (NLP) system will suggest likely Thai words to select from - like an auto-correct. This is a popular approach for Chinese, Japanese, and Korean typing; because it is literally impossible to map thousands of CJK characters onto a QWERTY keyboard.
For some strange reason no one has ever developed such a tool for Thai language. So as a data scientist with NLP experience, I immediately wanted to work on this project.
With my mind set on creating a "Thai Input Method Editor" I immediately came up with the playful name "Thaime" - for `THA-IME` and `THAI-ME` -> ไทยมี
However, I immediately hit a roadblock in my dev journey; namely, the nightmare that is the Microsoft TSF stack. Since I wasn’t very confident in using Linux earlier in my career, I only had developing for Windows on my mind. Yet trying to understand how to develop for Windows on my own was impractical, as someone with no C# / .NET / COM development experience. So after realizing I had zero chance to even get started, I had to put the project on hold…
Until today.
A Second Chance
Fast forward to 2025, after getting laid off for the first time in my life, I decided to use this extra free time as a sort of personal sabbatical; to work on projects I find interesting and rediscover my passions again. So I decided to start this blog, and try my hands again on the Thai IME project. This time, I have more programming experience, I’m now much more confident with Linux in general, and I have the help of modern LLMs.
After doing a lot of painstaking research, I finally got some vague idea of how I might develop my own IME. Resource on this topic is rather scarce (It doesn’t seem like too many people are trying to develop new IMEs, much less write about developing them.)
Conceptual Design
The first breakthrough came from this excellent Study Mongolian Blog. The blog introduced me to the Linux IBus - Intelligent Input Bus for Linux / Unix OS.
IBus is a Linux / Unix input method framework; which you can create your own simple IME on top of
However, the blog showed an implementation of the ibus-table based IME,
mapping specific Latin character combinations to a Mongolian characters (as in a lookup table).
This approach probably wouldn’t work very well with Thai for a variety of reasons:
such as the total number of consonant, vowels, and their combinations that exists;
and because of how tedious it would be to type out long Thai words character-by-character.
Instead, we would need to implement something akin to the Chinese Pinyin or Japanese Romaji - we want to transliterate Thai words phonetically into Latin, allow the users to type those Latin transliterations as input to the computer, then have an NLP system suggest relevant Thai word candidates as output.
Here’s an example of what I want:
| Latin Input | Thai Output |
|---|---|
| kam wa ruk gor mai kei pood dee dee | คำว่ารักก็ไม่เคยพูดดีๆ |
| pak nak mai ao nai jing jing | ปากหนัก ไม่เอาไหนจริงๆ |
| tae tummai tummai teung pood kam wa lakorn ork ma dai | แต่ทำไม ทำไมถึงพูดคำว่า ลาก่อน ออกมาได้ |
| dame da ne dame yo dame na no yo | … |

Thai people colloquially refers to this type of Latin transliteration as "Karaoke Typing"
Since my goal is to eventually have this IME be usable on both Windows & Unix, I learned that I will need to separate the core IME engine from the platform-specific “frontends”. I know that I still don’t want to have to deal with the Windows TSF as a frontend, so my first dev build will be on Linux with an IBus frontend.
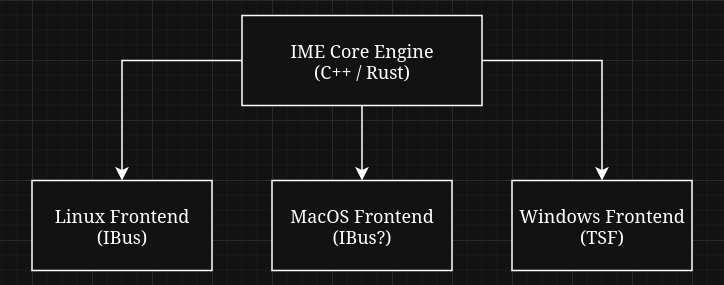
Probably unnecessary diagram of the IME architecture
Gaining a Foothold
Now for actually implementing the core systems, C/C++ is the option that I know will work on any platform, but I found this Korean Input Method Editor project which used Rust for its core. It’s been a very long time since I last worked with C/C++, I might as well consider it as learning a new programming language, so I thought why not learn something completely new like Rust instead?
This was a very big mistake.
I quickly came to learn that Rust-IBus integration is not at all straight forward. I fell into a deep, deep rabbit hole trying to learn about IBus, DBus, ZBus, then encountering Wayland problems with IBus, trying to find alternatives to IBus like SCIM and Fcitx, then finding additional confusion with XKB, and so much more historical Linux spaghetti.
After bashing my head against the wall for well over a week, I stumbled upon this ibus template repo by sheer luck. And what do you know, it provided both C and Python examples! I immediately tried copying the Python implementation and had something basic working within a day!
It needed a lot of refinements, but thanks to the ibus-anthy repo, I figured out how to improve the IME to a basic usable level (for a dev environment.)
Natural Language Processing
With a working IME prototype I can somewhat tinker with, I can finally get to work on the NLP part that I was initially so excited about. The problem statement here is something like:
Given some sequence of Latin characters, how do you find the right Thai word the Latin string is most likely to spell out, in a computationally efficient manner?
This here is the perfect task for a Trie - also known as a prefix tree. Tries are commonly used in auto-completes and spell checking algorithms; it is very fast to run, though can be pretty memory intensive.
Conceptually, the Latin string forms the trie’s edges, and the candidate Thai words will form the nodes. Practically, we can naively implement one as a simple Python dictionary (for now). When it comes to using the Trie, as we type in Latin characters, the characters are stored in a “pre-edit string”, which is used to traverse the trie (act as a key on a dictionary in our case). We then retrieve words at the nodes we land at, sort them from most likely option first, then show the ranked suggestions to the user.
However, there are a two things we need before we can generate the trie for our prototype:
-
List of common Thai words & their frequency data
Firstly, word frequency data is essential for providing relevant word candidates. We can combine various open-source Thai NLP datasets to generate our word frequency dataset. The word frequency data will be used to rank candidates, so we can show the most likely words first.
One key consideration is to balance the “styles” from different corpus to get good word suggestions. For example, the Thai Wikipedia corpus is mainly made up of formally written articles, whereas the Wongnai corpus is mainly informal internet reviews. Yet the Thai Wikipedia corpus is much larger than the Wongnai corpus, and thus will strongly bias the term frequency data towards a formal writing style, unless managed properly.
By selecting a variety of different NLP corpus and balancing the importance of each corpus, we can ensure that the word dataset will be both broad and representative of what the user will type.
-
The Latin transliteration of said Thai words
Secondly, we need a dataset of how to type out these Thai words in Latin. Unfortunately, there doesn’t appear to be any existing datasets we can readily use, and manually labelling all this data would also be impractical. To further complicate matters, there are no agreed upon standards for transliterating Thai words into Latin. Each person spells Thai words differently, even location names are commonly spelled in multiple ways.
To get around this issue, I’ve used LLMs to generate an initial transliteration dataset. By simply prompting an LLM to provide as many Latin transliterations for a given Thai word, I can acquire a large amount of transliteration data at very little cost. Understandably, this initial dataset will not perfectly match how actual human spells, but it will get us started with a prototype. (We can focus on getting better transliteration data later on.)
These were relatively simple to implement. After collecting the right datasets, the actual Python implementation took a few days to work on, before I have both prerequisites for the trie generation. The trie generation afterwards is also rather trivial, just combining the two datasets into one massive Python dictionary.
In the end, I gathered over 100K Thai words from 4 different NLP corpus, but I selected only the top 10K words for the initial implementation. The LLM prompting step took about an hour to execute and costed about 40 cents (gpt-4.1-mini). The resulting Trie fits into a 8MB JSON file - which was smaller than I expected. Though there are plenty of room for optimization, for a first prototype, this is plenty fine.
Future Improvements
Here are some future improvement ideas I have, in terms of the NLP.
Currently, the trie only ranks words by its term frequency data alone. We don’t rank it by additional contexts like nearby words or user preference. In the future, I plan to incorporate common NLP techniques like ngrams, skip-grams, hidden markov models, and more, to better rank candidate words.
I also plan to improve on the Trie implementation. Currently, I am just using a naive Python dictionary implementation, which is not space efficient, and might require too much memory if I start to include +100K words.
Finally, the Latin transliteration data also needs to be improved. I’m a bit less certain on where I will get the data for this, but I think there are two options; a (voluntary) user typing statistics telemetry, and an online survey. Collecting real world user typing and conversion stats is by far the most accurate. We could collect massive amounts of real typing data with that; though there are many privacy concerns to consider. An online survey could be an easier approach, but it will definitely not be as scalable or reliable as user telemetry. In the end we might have to do a bit of both.
Conclusion
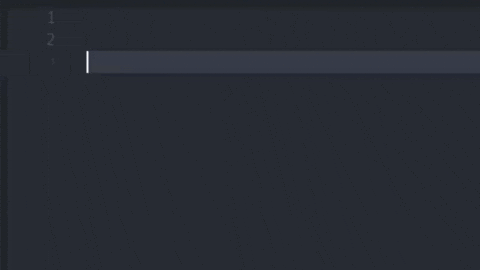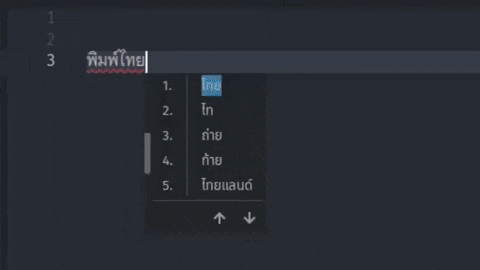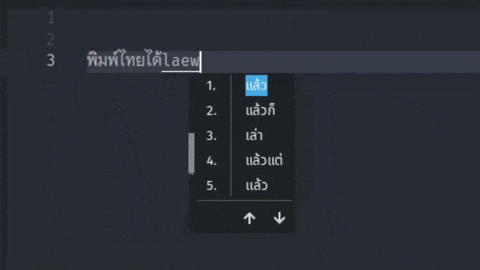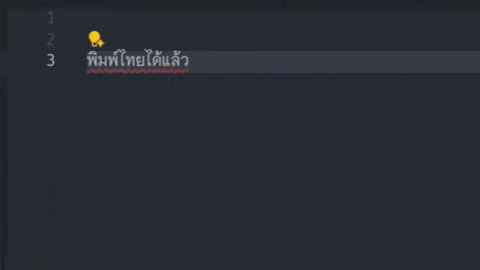
And with a few tweaks to incorporate the trie into the Python IME, I now have a working Thaime prototype! You can find this project at github.com/mimocha/thaime. I’m only just getting started, but I am excited to work on this passion project of mine.
Please wish me the best of luck!